machine-learning-nanodegree
Class notes for the Machine Learning Nanodegree at Udacity
Go to IndexClustering
K-Means
K-Means Algorithm
- Add
Kcentroids to the data at random positions.

- Associate each data point to the closest centroid (aka association step)

- Move the centroids to the mean distance between all associated points

- Repeat step 2 and 3
ntimes, or until some other stop-condition has been met.
K-Means is not deterministic
The initial position of the centroids will influence the final outcome of the algorithm. See the example below:


To solve this problem, we run the algorithm multiple times and average the results.
K-Means and sklearn
class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300,
tol=0.0001, precompute_distances='auto', verbose=0,
random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
n_clusters: number of centroids to initialize. Also defines the number of clusters to be found. This should be set using domain knowledge of the problem.max_iter: number of iterations (associate points, move centroids, repeat) to be run.n_init: number of times the algorithm will run before outputing the results.
K-means references
Single Linkage Clustering
Single Linkage Clustering Algorithm

Soft Clustering

- Can assign the same point to multiple clusters
- Probabilistic approach
Expectation Maximization

Expectation Maximization Properties

Clustering Properties

Impossibility Theorem

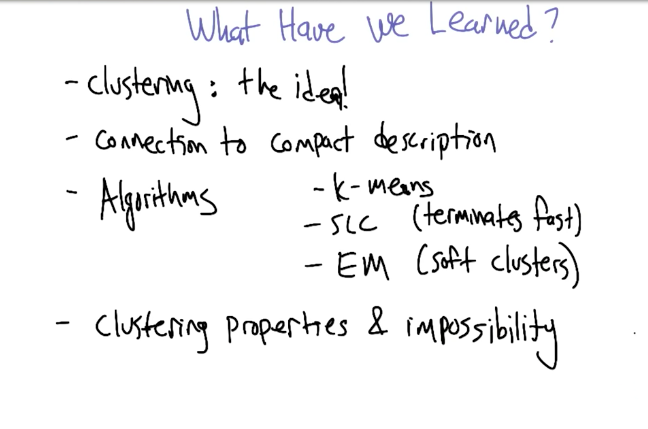
Summary